

PIX SPI JVM performance
Scalability refers to the ability to do more work in proportion to the increase in capacity of the system doing the work.
When we take a certain system that we know does work on a machine with one processor, we expect that same system to do twice as much work on a machine with two processors.
In practice, due to the existence of various types of bottleneck in the system, from the hardware to the operating system to the application, real scalability will be lower.
The aim of this work is to evaluate the performance of the new PIX SPI JVM 2.0 with an emphasis on the concurrency variable, i.e. the amount of work being done concurrently.
Taking a fixed architecture, we carried out measurements by varying the amount of concurrency, in order to check the impact on the latency (time of an operation) and throughput (rate of operations per unit of time) metrics.
Immediately below are the results of this exercise, and further on is a description of our method. Prodist customers interested in a performance study of their architectures with our tool need only ask our technical support team for an appointment.
RESULTS:
We ran our measurement tool on a machine with 8 processors and a Prodist STS cluster with 2 servers on machines with 8 processors each. Considering an STS server as a cryptographic coprocessor, the configuration has a total of 24 processors, 8 generic and 16 cryptographic. We measured the times of an mTLS 1.2 handshake and an SPI signature.
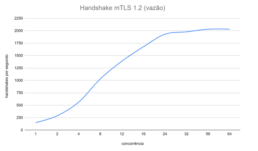
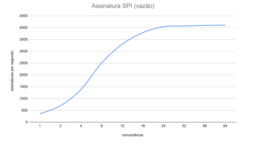
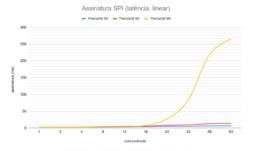
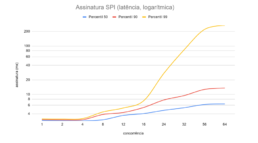
In this architecture, we obtained 2000 handshakes or 4000 signatures per second, with both, in the 99th percentile, below 50 milliseconds.
Flow, in both metrics, grew linearly up to competition level 8 with an imperceptible impact on latency; from level 16 onwards, flow growth slowed and the impact on the 99th percentile of latency accelerated perceptibly; from level 24 onwards, the gain in flow ceased completely.
This exercise suggests that the ideal ratio of processors for the PIX SPI JVM is 1 generic to 2 cryptographic. In a future study, we will verify this hypothesis.
Handshake mTLS 1.2
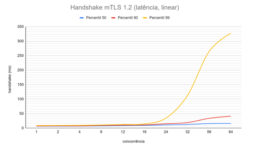
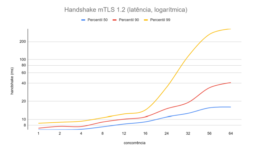
SPI signature
METHODOLOGY:
Architecture
We use AWS EC2 with an isolated VPC and three machines connected to this VPC in the following configuration:
Two c5a.2xlarge machines with Windows Server 2019 and STS Server 7.0.3.
A c5a.2xlarge machine with Ubuntu 22.04 and the PIX SPI JVM microbenchmarking tool.
Both STS Servers with a domain configured for the RSFN 3 protocol containing an ISPB with a private key, and the read timeout parameter set to 1000.
Cluster configuration file edited for the two servers above with the same 50% weight.
The JVM used was JDK 11.0.22, OpenJDK 64-Bit Server VM, 11.0.22+7-post-Ubuntu-0ubuntu222.04.1.
The PIX SPI JVM microbenchmarking tool is an application of the Java Microbenchmarking Harness (JMH), integrating:
- dev.prodist.certificates.jvm:certificates-sts:1.0-42+499d69f8
- dev.prodist.jca:jca:1.0-61+558a0557
- dev.prodist.keys.jvm:keys-sts:1.0-121+bc96d6e2
- dev.prodist.pix.spi.jvm:pix-spi-core:2.0-1194+22119c0a
- dev.prodist.sts.jvm:sts-api:2.0-302+7b32d934
- org.apache.santuario:xmlsec:2.3.1
- org.openjdk.jmh:jmh-core:1.37
This is the command line template used to perform measurements:
java -jar pix-spi-core-2.0-1194+22119c0a-jmh.jar -bm ${mode} -jvmArgs ‘-
Ddev.prodist.pix.spi.licensing=file:///home/ubuntu/app-27.lic’ ‘-
pconfigurationFile=politicamsg.xml’ ‘-pmessageSize=1024’ -rf csv -rff ${mode}-
${concurrency}.csv -t ${concurrency} -tu ${unit} HandshakeBenchmark.handshakeWithKeyInSts
SignBenchmark.sharedWithKeyInSts
The tool runs five series of five discarded iterations and five counted iterations, each iteration
running for 10s. For more details on the modes of operation and the metrics obtained, see the JMH documentation.
documentation.
Handshake mTLS 1.2
We measured the time of an mTLS 1.2 handshake applying SSLEngine directly without TCP connections, using the same procedure as in the automated test suite.
A handshake is processed locally with only one RSASSA/PKCS1 cryptographic operation (for client authentication) delegated to the STS cluster.
The server's SSLEngine was configured with a private key in memory using the JDK's standard KeyManager and TrustManager.
The customer's SSLEngine was configured with a private key on the Prodist STS cluster using the CoreKeyManager and CoreTrustManager of the Prodist PIX SPI JVM, just as it would be in production.
SPI signature
We measured the time it takes to draw a message and sign it with a single shared instance of the signer.
An SPI signature is processed locally with only one RSASSA/PKCS1 cryptographic operation delegated to the STS cluster.
We draw a new message each time to avoid the effect of always accessing the same message from the processor cache. The time taken for this draw contributes negatively to the measurement, as this effort does not exist in production. To support internal R&D activity, the tool includes a special measurement called random which measures exactly this time. In the environment of this exercise, the average time for a random is 12 μs.